Walkthrough
Getting Started
Implementing AiStreamliner is designed to be straightforward, even for teams without extensive Kubernetes expertise. You’ll begin by cloning our GitHub repository and running the intuitive installation script.
The platform requires a Kubernetes cluster version 1.32 or higher, offering flexible deployment across any major cloud provider or on-premises environment. We’ve conducted extensive testing with AWS EKS, Azure AKS, Google GKE, and self-managed Kubernetes deployments, ensuring robust compatibility. The installation script handles the deployment of all components with sensible defaults, meaning most users can be up and running in under an hour.
For those with specific requirements, AiStreamliner provides extensive configuration options, including resource allocation, persistent storage configuration, security settings, and seamless integration with external systems. While Kubernetes knowledge is helpful, it’s not a prerequisite for successfully deploying and leveraging AiStreamliner.
Data Management Workflow Steps

Once AiStreamliner is installed, establishing your data management workflow is a seamless process. You’ll begin by registering your data sources directly through the intuitive dashboard, making them readily available across the entire platform. AiStreamliner supports a wide range of sources, including local files, object storage buckets, database connections, and streaming data.
For experimentation, data scientists can easily create branches of datasets without impacting your production data. This allows for flexible exploration of different data preparation approaches or feature engineering techniques in isolated environments. To ensure data quality, you can set up robust validation pipelines using simple YAML configurations. These pipelines are designed to automatically check for critical issues like missing values, outliers, and distribution shifts.
Once you’re confident in a dataset version, you can commit it to make it immutable and available for model training. Throughout this entire process, AiStreamliner automatically tracks detailed data lineage, capturing the intricate relationships between your datasets and the models trained on them. This comprehensive tracking is absolutely essential for ensuring reproducibility, maintaining compliance, and facilitating efficient debugging.
Training and Evaluation Steps
AiStreamliner provides a standardized yet flexible workflow for model training and evaluation, ensuring consistency and reproducibility across all your projects. You’ll begin by defining your training workflow steps through Kubeflow pipelines, which provide a clear structure for your entire process.
To maintain meticulous records, you’ll configure experiments in MLflow, automatically tracking all parameters and metrics. Training jobs can be launched directly from the intuitive dashboard, with resource allocation handled automatically to optimize performance. For deep insights, AIM allows you to visually compare results across multiple runs, making it easy to identify the best-performing models and understand underlying patterns.
Once satisfied with your model’s performance and validation, you can register these validated models directly in the central model registry, making them readily available for deployment. This structured approach balances standardization with the flexibility needed to support both beginners and experienced practitioners, providing clear guidance without being overly rigid.
Deployment and Monitoring Steps
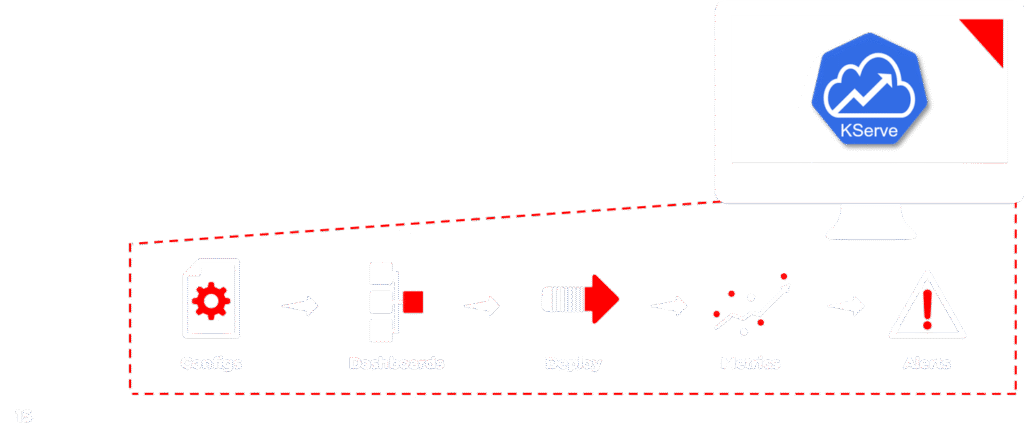
When your models are ready for prime time, AiStreamliner ensures a smooth and low-risk transition to production. You’ll configure serving directly through our intuitive dashboard using KServe, which provides a user-friendly interface for setting up inference services, managing resources, and controlling model versions with ease.
To ensure continuous performance, you can quickly set up comprehensive monitoring dashboards within the platform to track key metrics like inference time, throughput, and system health in real-time. This consolidated view offers critical visibility into your model’s performance and operational status in production.
Deploying to production is streamlined to just a few clicks, with advanced options for canary deployments or A/B testing. This significantly reduces the risk associated with model updates, allowing for safe, gradual rollouts. Furthermore, you can set up automated alerts based on performance thresholds or drift detection, ensuring appropriate team members are immediately notified when metrics deviate from expected ranges or when data drift is detected. This comprehensive approach to deployment and monitoring truly closes the loop on the entire ML lifecycle, guaranteeing reliable and high-performing AI solutions.