Challenges in AI Operations
Why this Matters


Just 18 months ago, our R&D group at Ardent faced a significant challenge: optimizing our infrastructure for AI and ML applications. We found that while numerous tools existed, achieving true integration for complex workflows was a hurdle, leading to slow deployments and increased complexity. Our goal was to leverage open-source components to establish a robust and scalable baseline, driving us to build specific tools and applications primarily focused on AI and ML while keeping costs low.
A major pain point was the time and effort required to deploy and manage environments across various providers, both on-premise and in the cloud. We envisioned a streamlined, one-click deployment solution that could rapidly provision environments based on project needs. This critical insight and the drive to simplify our operational processes led directly to the creation of AiStreamliner.
The promise of AI and ML is exciting, but its full potential can only be realized with the right infrastructure. We understand that many organizations face similar operational hurdles, and AiStreamliner was built to address these challenges head-on. It’s our solution to empower you to unlock the true power of AI and ML, efficiently and without unnecessary complexity.
The Challenge: AI Operations at Scale

As organizations scale their AI/ML initiatives, they often encounter a fragmented ecosystem. Think about it: you might be using different tools for data versioning, experiment tracking, model registry, and deployment, each with its own interface and learning curve. This disparate setup makes creating efficient workflows a constant challenge.
Furthermore, Large Language Models (LLMs) introduce unique complexities. They are typically much larger, demanding specialized hardware and distinct evaluation metrics, adding another layer of operational complexity that traditional MLOps tools might not fully address.
When you’re running a few experiments, manual processes might seem manageable. But as your team grows to dozens of data scientists deploying hundreds of models, the need for robust automation and standardization becomes critical. Without it, managing these operations is difficult, costly, and can significantly slow down your ability to deliver and innovate.
Our Open-Source Solution
An Open-Source Unified Approach
AiStreamliner is a comprehensive open-source platform designed to integrate the entire ML lifecycle on Kubernetes. We’ve built it to provide unified workflows from data management through deployment and monitoring, with special consideration for the unique demands of Large Language Models (LLMs). This end-to-end automation accelerates innovation by streamlining experimentation, freeing your data scientists to focus on model improvement rather than operational overhead.
By leveraging Kubernetes, we ensure the platform scales efficiently with your needs while maintaining crucial flexibility. Our platform-agnostic design means you can deploy AiStreamliner across various cloud providers or on-premises, completely avoiding vendor lock-in.
The power of AiStreamliner lies in its 100% open-source nature. This gives you complete control and extensive customization options, allowing you to tailor the platform precisely to your organization’s specific requirements and integrate seamlessly with your existing infrastructure.
Platform Architecture Components
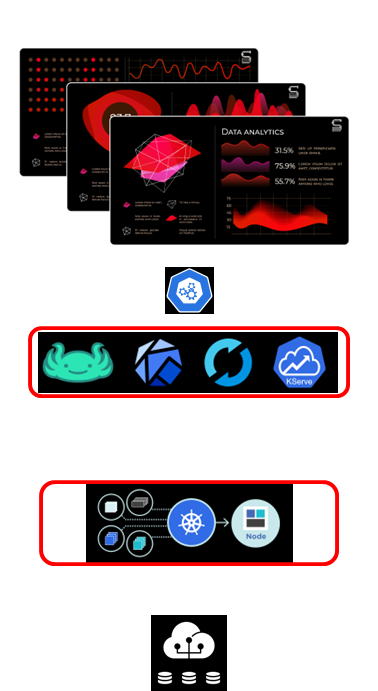
Our solution’s architecture is built on four main layers, designed for flexibility and robust performance. At the top, we’ve enhanced the Kubeflow dashboard to serve as our primary user interface, providing a familiar experience for Kubeflow users while significantly extending functionality.
The service layer houses our core components and exposes well-defined APIs. This design ensures loose coupling between services, enabling you to easily replace or extend individual components as your needs evolve. We leverage Kubernetes’ native capabilities for service discovery, load balancing, and self-healing, forming the robust orchestration layer that handles deployment, scaling, and resource management with efficiency.
Finally, the storage layer utilizes persistent volumes, offering flexible options from local disks to advanced cloud-native storage solutions for managing your data and models. This layered approach ensures the platform is both modular and extensible, allowing you to start with core components and gradually add functionality as your requirements grow.
Initial Core Components

AiStreamliner harnesses the power of leading open-source technologies to deliver a comprehensive and integrated MLOps platform. We’ve carefully selected and woven together best-in-class tools to provide a seamless experience from data versioning to model serving.
- Kubeflow: This is the backbone for workflow orchestration and training. Its containerized approach ensures consistent, reproducible ML workflows across any infrastructure, with automated scaling for resource-intensive training. Data scientists can focus entirely on model development, liberated from infrastructure management.
- MLflow: Serving as our central hub for experiment tracking and model registry, MLflow offers a language-agnostic design that supports any ML library. It provides a comprehensive record of all parameters, metrics, and artifacts, establishing a single source of truth for all your production models.
- KServe: For model serving and inference, KServe provides serverless inference with automatic scaling and multi-framework support via a unified API. Its production-ready features like canary deployments, traffic splitting, and GPU acceleration enable safe, high-performance model delivery.
- LakeFS: Bringing Git-like version control to your data, LakeFS allows for branching, merging, and atomic commits on large datasets without duplicating storage. This ensures experiment reproducibility and enables safe, controlled data transformations.
- AIM: For specialized deep learning experiment tracking, AIM offers purpose-built visualization tools. These enable powerful side-by-side evaluation of training runs, providing enhanced insights, especially for visual and time-series comparisons.
By integrating these robust components, AiStreamliner provides a unified and powerful environment, allowing your teams to innovate faster and manage the entire ML lifecycle with unprecedented efficiency and control.
AiStreamliner Dashboard
We’ve extensively modified the Kubeflow dashboard to serve as your primary interface for AiStreamliner, delivering a user experience that simplifies complex ML operations. This custom dashboard provides integrated visibility across all components, from data management through deployment, significantly reducing context switching and making your entire workflow more cohesive.
A key enhancement is the addition of specialized components for managing prompt engineering workflows and evaluating Large Language Model (LLM) outputs. This focus makes it easier to manage and deploy new model paradigms alongside traditional ML, ensuring comprehensive support for your diverse AI initiatives.
The result is an intuitive interface that streamlines your entire ML lifecycle. For every user logged into the system, the dashboard provides direct links to all integrated components and essential information, such as pipeline statuses and detailed model information. Furthermore, we’ve implemented robust role-based access controls to manage permissions based on team responsibilities, ensuring secure and efficient collaboration.
Data Management with LakeFS

If you were wondering, “Which version of the dataset was used to train this model?”, you’ll deeply appreciate AiStreamliner’s approach to data management. We integrate LakeFS to provide Git-like version control for your datasets, directly addressing the critical challenge of data versioning in ML workflows.
This powerful capability transforms data management from a pain point into a streamlined process. Multiple data scientists can work on different versions of the same dataset without conflicts, allowing for parallel experimentation and ensuring data integrity. When something goes wrong, you can simply roll back to a known good state, offering unparalleled safety and control.
LakeFS also creates a comprehensive audit trail by tracking relationships between datasets and the models trained on them. This is essential for regulatory compliance and debugging. By bringing the same level of rigor and control that version control systems like Git brought to software development, we ensure experiment reproducibility and enable safe data transformations for your entire ML lifecycle.
Model Development Workflow

For efficient and reliable model development, we’ve engineered a fully integrated workflow within AiStreamliner. Our process begins with data managed by LakeFS, ensuring every dataset is versioned and reproducible. This foundation seamlessly integrates with Kubeflow Pipelines, which orchestrates training workflows, making them both repeatable and highly scalable.
Throughout the development cycle, MLflow comprehensively captures hyperparameters, metrics, and artifacts, ensuring every experiment is fully documented and completely reproducible. For deep learning models, AIM provides advanced visual comparisons across training runs. These specialized visualizations help identify subtle patterns that might not be obvious from metrics alone, offering deeper insights into model performance.
Finally, automated validation pipelines are critical before deployment. These can include unit tests for model code, statistical tests for outputs, fairness evaluations, and rigorous performance benchmarks. This integrated and robust approach ensures unparalleled consistency and reproducibility across all experiments, while maintaining comprehensive records every step of the way.
Deployment and Serving with KServe
Moving models from development to production is often a major bottleneck in ML workflows. AiStreamliner addresses this by integrating KServe, which streamlines this process with a consistent and robust deployment mechanism. KServe supports multiple ML and LLM frameworks, empowering your teams to use the tools they’re most comfortable with rather than being forced into a specific framework.
KServe provides serverless inference capabilities, allowing it to scale from zero when there’s no traffic to handling thousands of requests during peak periods, ensuring optimal resource utilization. Its advanced features include sophisticated canary deployments and traffic splitting, allowing you to gradually shift traffic and revert if issues arise. This approach significantly reduces the risk associated with model updates in production.
KServe’s architecture is particularly well-suited for serving complex models, including large language models (LLMs). It provides specialized optimizations like quantization, batching, and caching to significantly improve throughput and reduce latency. This ensures your deployed models perform at their best, delivering powerful and efficient inference in real-world scenarios.